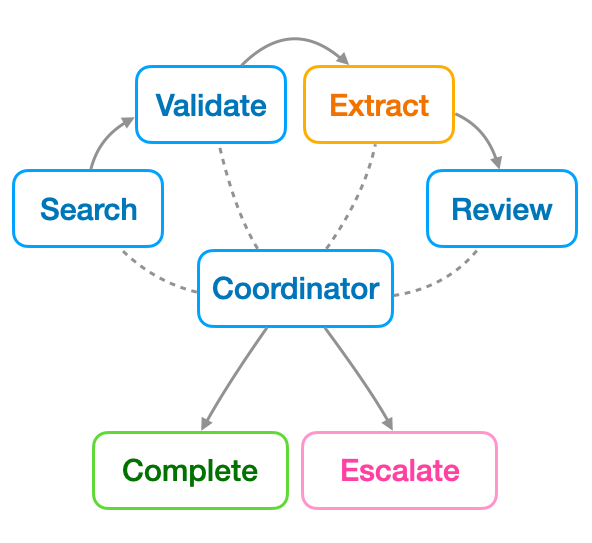
Filling the Gaps in Police Shooting Data with an Agentic AI Pipeline
AI Agents
Data
Evaluation
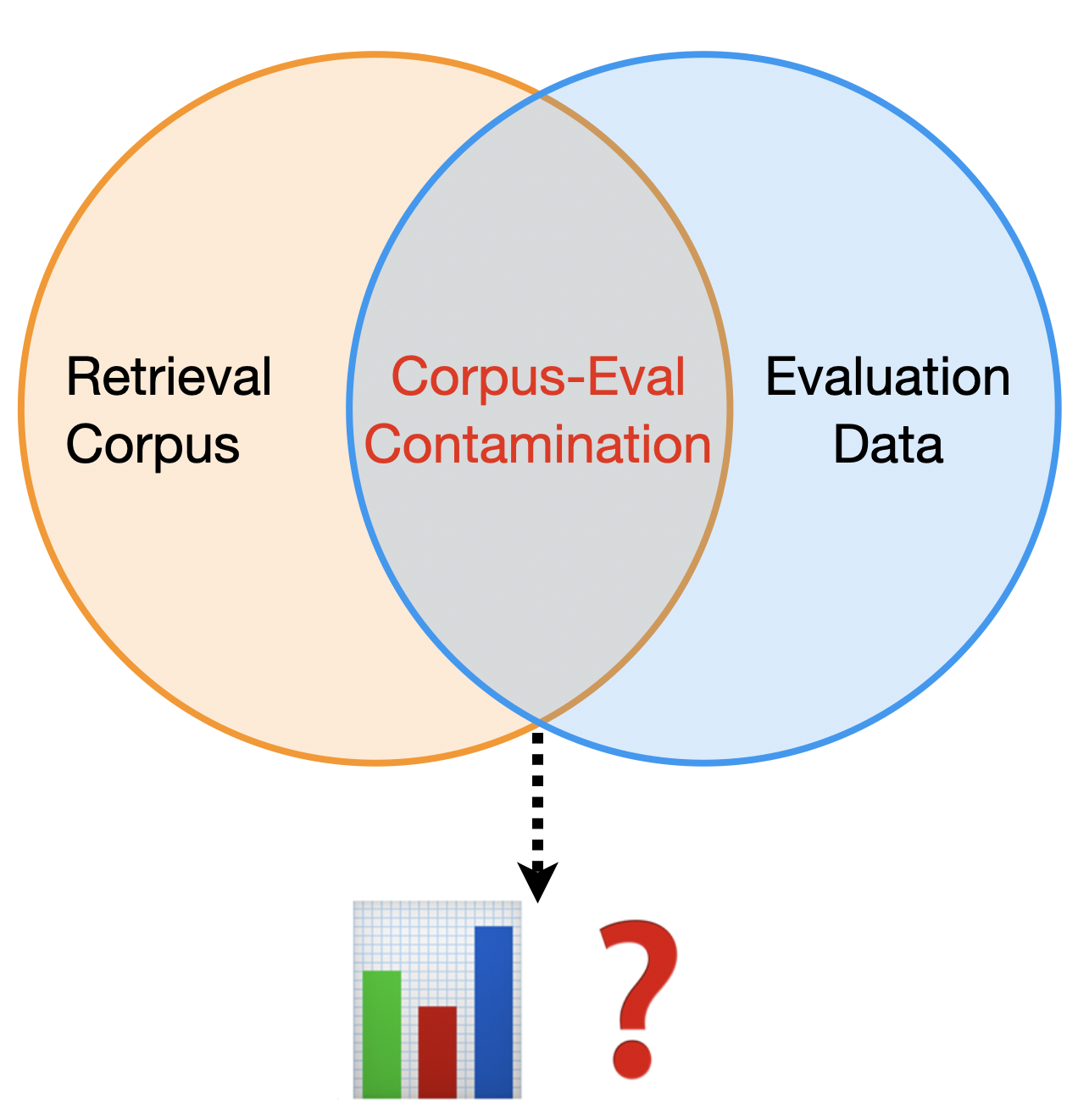
The Corpus-Provenance Gap in RAG Evaluation
LLM
Evaluation
MLOps
Data

The AI SDK Adoption Problem: When Conway’s Law Meets AI Engineering
Leadership
MLOps
LLM

LangGraph Error Handling Patterns in Production
AI Agents
LLM
MLOps

Essential qualities of ML tech leads
ML
Leadership
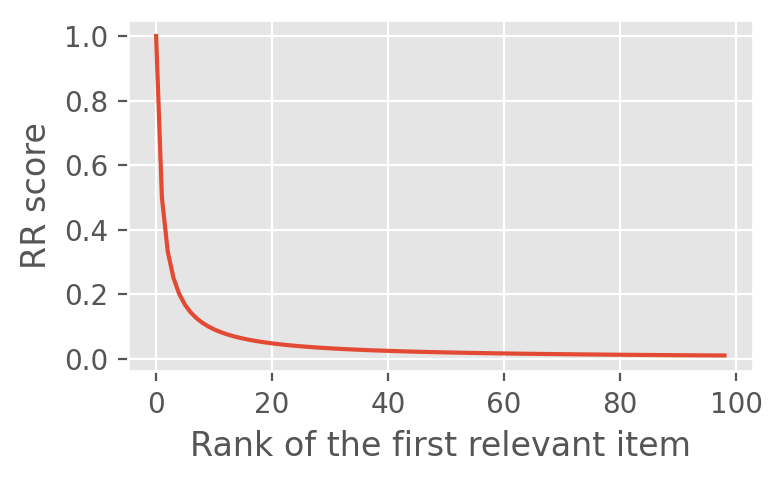
Ranking metrics: pitfalls and best practices
ML
Learning to Rank
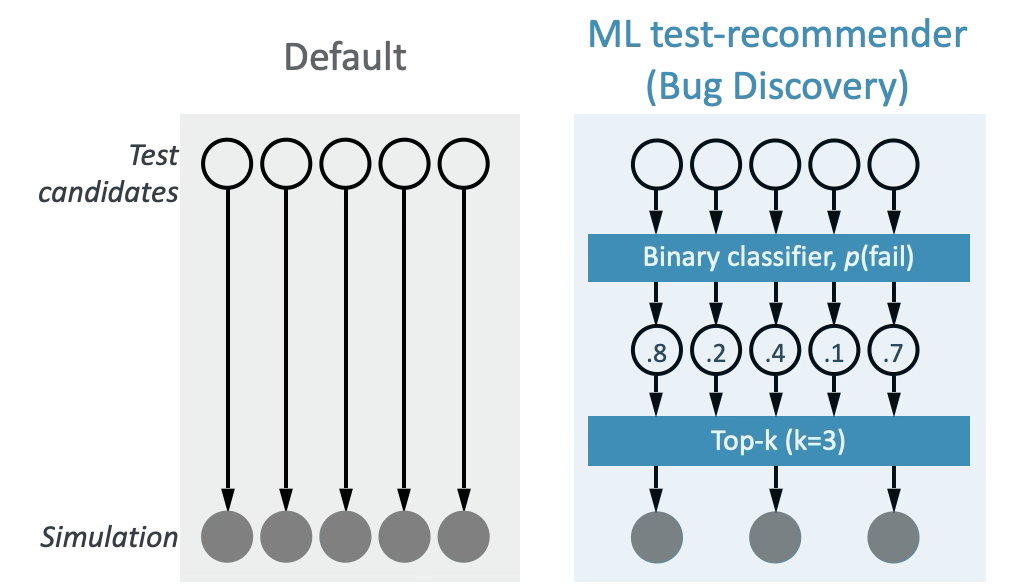
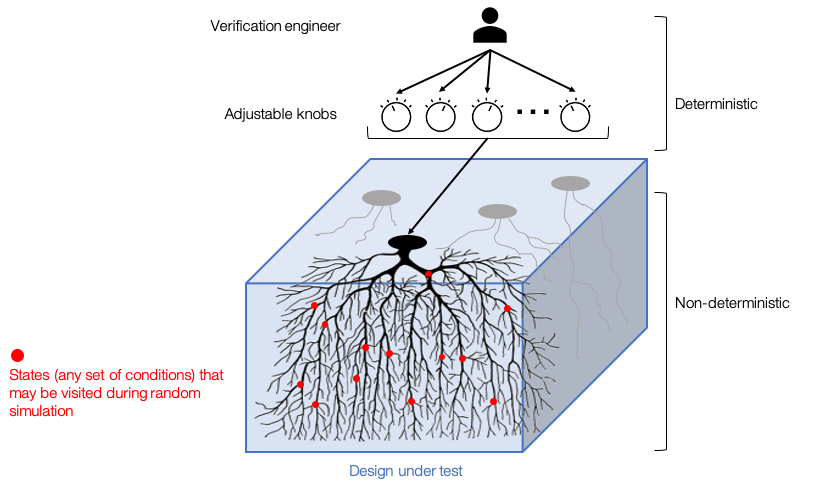
Learning-to-rank for hardware bug discovery
ML
Verification
Learning to Rank

Model tuning with Weights & Biases, Ray Tune, and LightGBM
ML
MLOps
Visualization
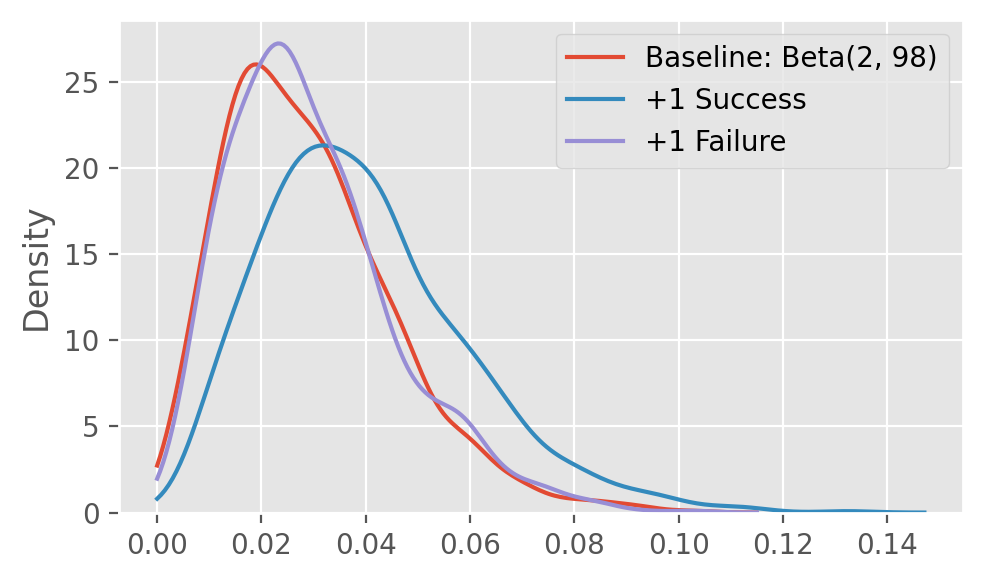
Thompson sampling in practice: modifications and limitations
ML
Verification
Bayesian

Building effective ML teams: lessons from industry
ML
Collaboration
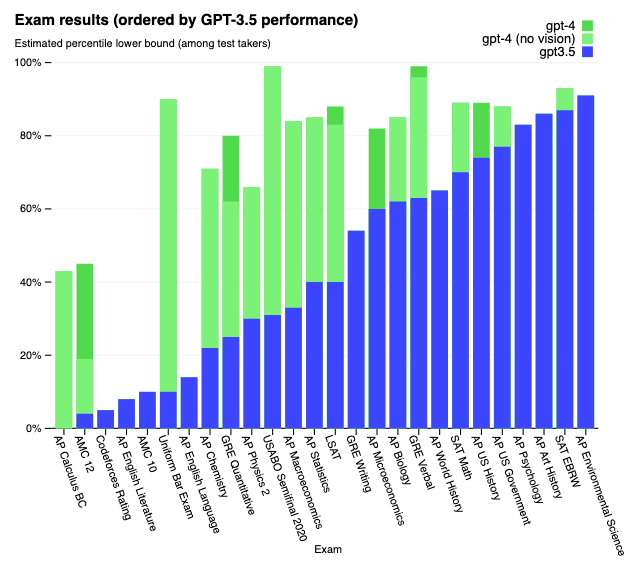
Building datasets for model benchmarking in production
ML
MLOps
Data
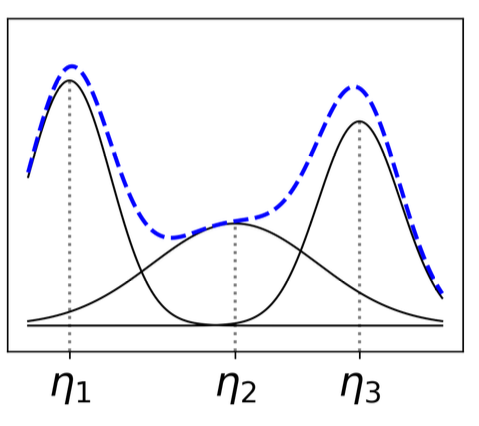
Modeling tabular data using conditional GAN
Paper Review
LLM
ML
Tabular data synthesis (data augmentation) is an under-studied area compared to unstructured data. This paper uses GAN to model unique properties of tabular data such as mixed data types and class imbalance. This technique has many potentials for model improvement and privacy. The technique is currently available under the Synthetic Data Vault library in Python.
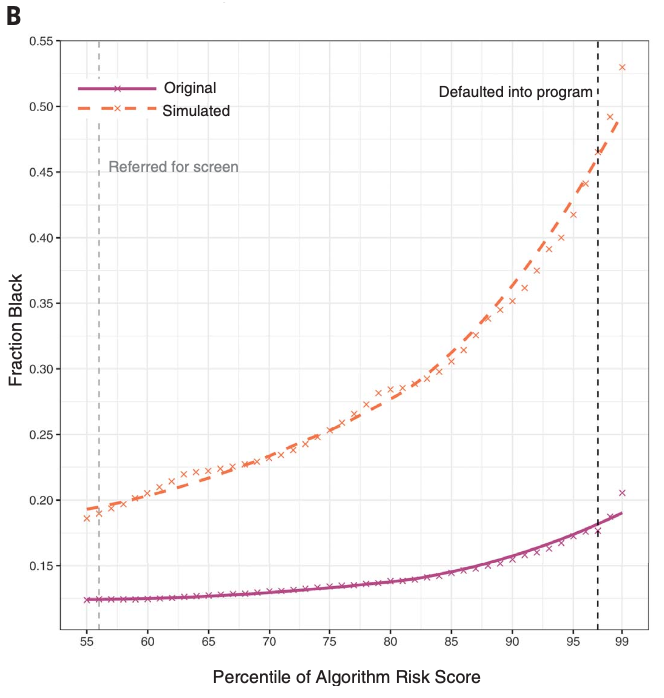
Dissecting racial bias in an algorithm used to manage the health of populations
Paper Review
ML
Responsible AI

Algorithmic decision-making and fairness (Stanford Tech Ethics course, Week 1)
Responsible AI
Criminal Justice


Constitutional AI: harmlessness from AI feedback
Paper Review
LLM
ML
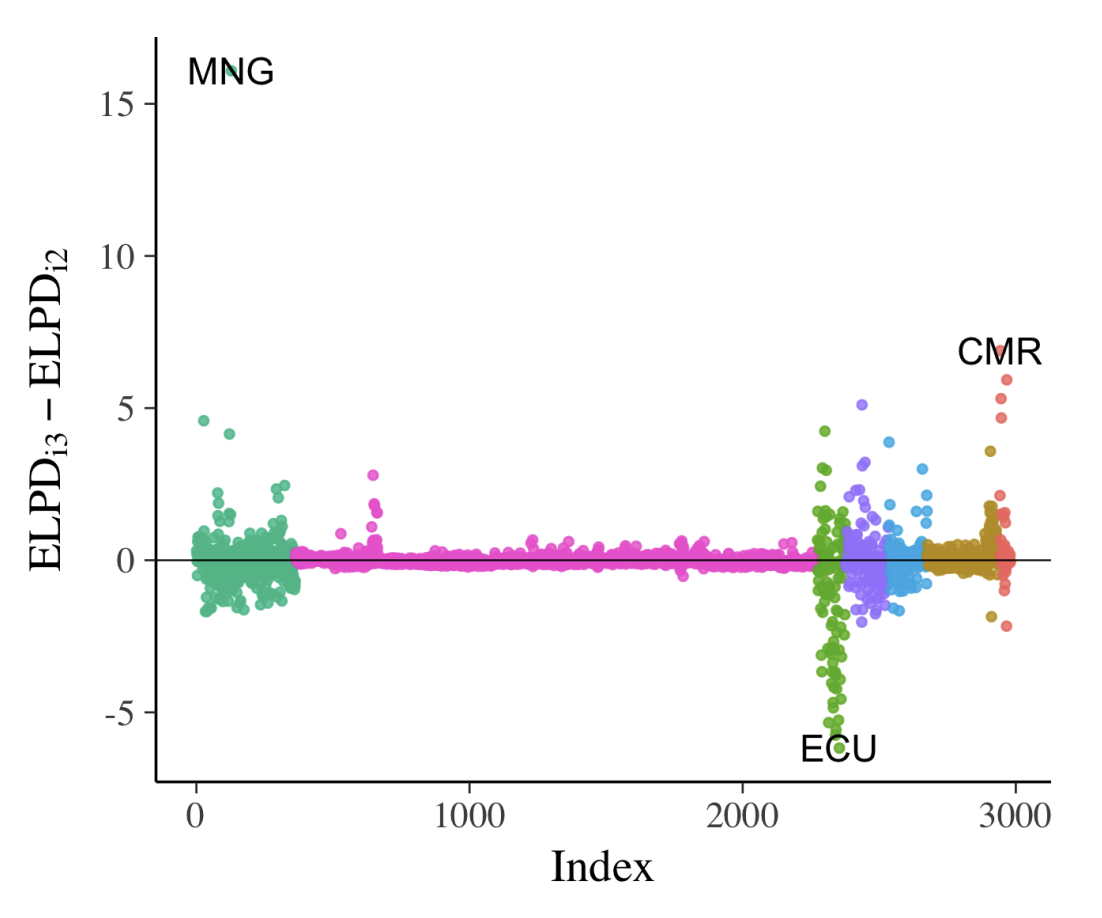
Visualization in Bayesian workflow
Paper Review
Bayesian
Visualization
ML



“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI
Paper Review
Data
Responsible AI


Police shooting in Texas 2016-2019
Criminal Justice
Visualization
Volunteering

Tutorials at FAccT 2021
Conference
Responsible AI
ML

No matching items